
the podcast bert built.
making the world’s most boring podcast with notebooklm

Recently, I helped co-found the Convergence Center for Law, Design, and AI. As part of that, I’ve been diving deeper into the legal space, learning as much as I can. I’ve been getting a lot of valuable insights from friends and colleagues, who’ve started sending me resources… one of which is a GitHub post—a collection of over 13,000 companies working in legal tech. (RegTech, LegalTech, CivicTech… so many terms!)
These massive, unwieldy qualitative datasets are my shit. It’s like a box of puzzles. How do I put it together and make sense of all this information?

Recently I started playing with NotebookLM*, and have been obsessed with the conversational “deep dive” feature, where it takes the documents you’ve provided and generate a podcast-style audio. For example, here is one created from the Convergence Center’s mission. (No need to listen to the whole thing… just check it out and jump to the more interesting things following…)
*NotebookLM is a personalized AI research assistant created by Google, powered by its Gemini 1.5 Pro model. It helps users organize, analyze, and synthesize information from their own documents. By uploading relevant sources, users can receive insights and summaries tailored to their specific needs, with citations that are grounded in the original material. Essentially, it assists in turning raw data into organized, actionable insights while maintaining privacy control over your personal data.
It’s like a personal, mini RAG database. (50 documents max for now)
At first, the results were… alright. Not great. It jumped around and hyper-focused on specific themes.
I realized I needed to first show it what top level information to structure the discussion around. I can’t directly instruct the “deep dive” generation, but I can process the seed data more effectively.
Maybe pre-categorize the data first into more meaningful groups? So, I experimented with topic modeling to tag each company based on the services they offer, clustering them into more distinct macro characteristics.
Once I had done that, I fed the refined data back into NotebookLM, and this time, the result became a much more relevant and insightful overview of the whole space.
Final Podcast… Enjoy…
This rest of the newsletter strolls through the process. Let’s dive in.
NLP: An Old Dog with New Tricks
For tasks like this, I’ve found BERTopic to be an ol’reliable. It’s great for quickly extracting meaning from large datasets, and I rely on it for its simplicity and effectiveness. Following standard NLP hygiene, I start by filtering out stopwords and punctuation to keep the focus on the relevant content.
From there, I let BERTopic do its thing—no major parameter tweaking yet, just using the default settings (like embedding model (default: all-MiniLM-L6-v2), min number of clusters (I think 10?), etc.) The result? 146 distinct topics, each represented by characteristic keywords that give us a sense of what the companies in each group are all about.

Here’s a sample of the first eight most prominent topics, which provide an early look into how the companies are clustered based on their services.

By taking a hierarchical view, we can also see how these topics relate to each other—specifically, how often certain topics co-occur or how different services overlap. This gives us a powerful visual of the connections within the legal tech landscape.

But what I find most intriguing is the semantic space that emerges when we map out all the company descriptions. Every company is plotted based on how similar their services are to one another. You’ll notice some niche specialties—like “cannabis law” or “flight compensation”—drifting off into their own corners of the map, while the majority of companies cluster tightly together.

Within that larger cluster, you’ll find smaller islands of specialization, revealing the more granular patterns in this space.

Next, I annotate each company with the topics generated by BERTopic. This step helps connect the dots, linking companies to broader themes and creating a higher-level structure for NotebookLM to navigate. Given that Google’s method for chunking data in NotebookLM remains unclear, I decide to take control of the process myself and chunk the data according to my analysis.
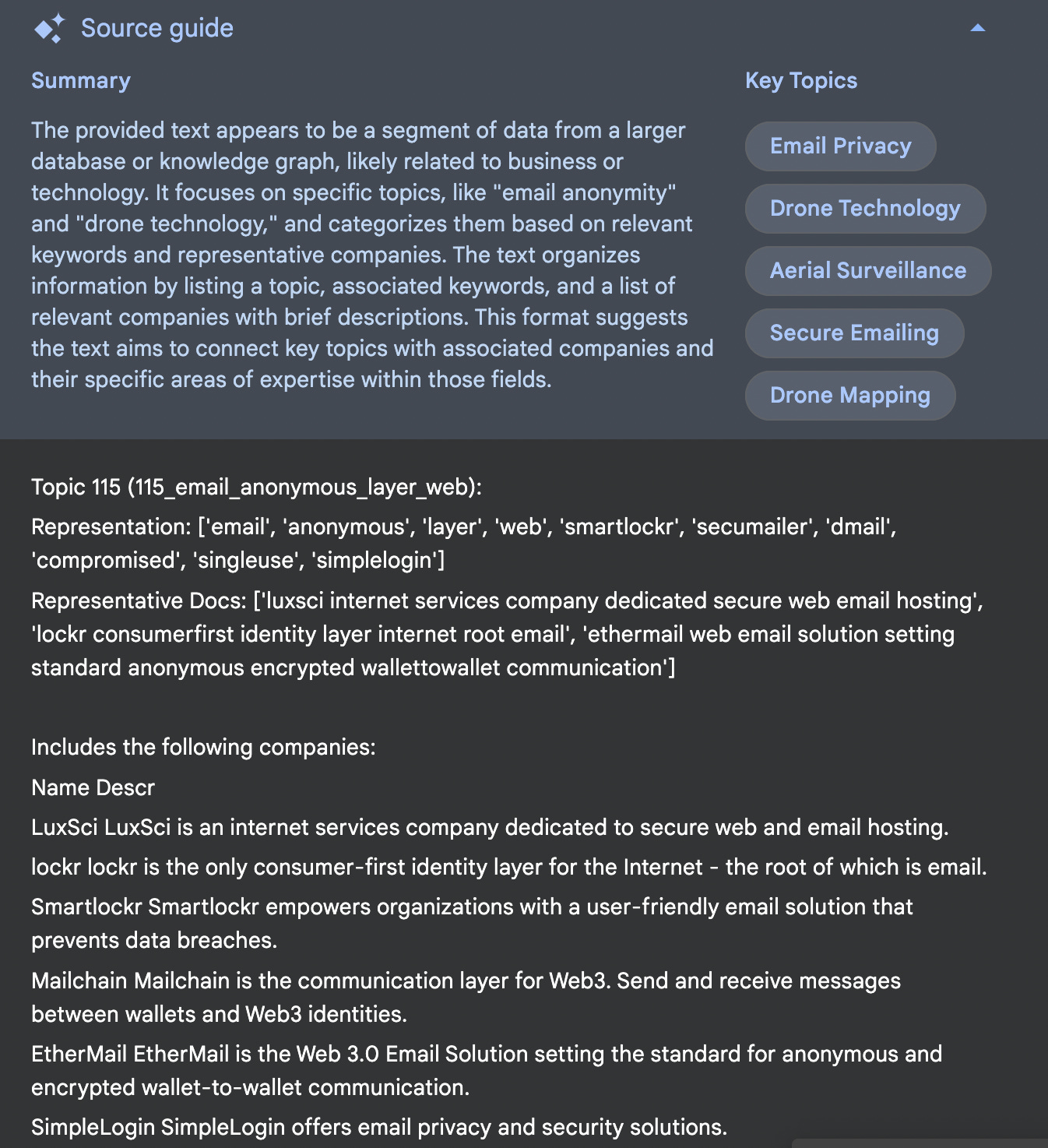
Finally, after chunking and uploading all the documents to NotebookLM, I generate the podcast!
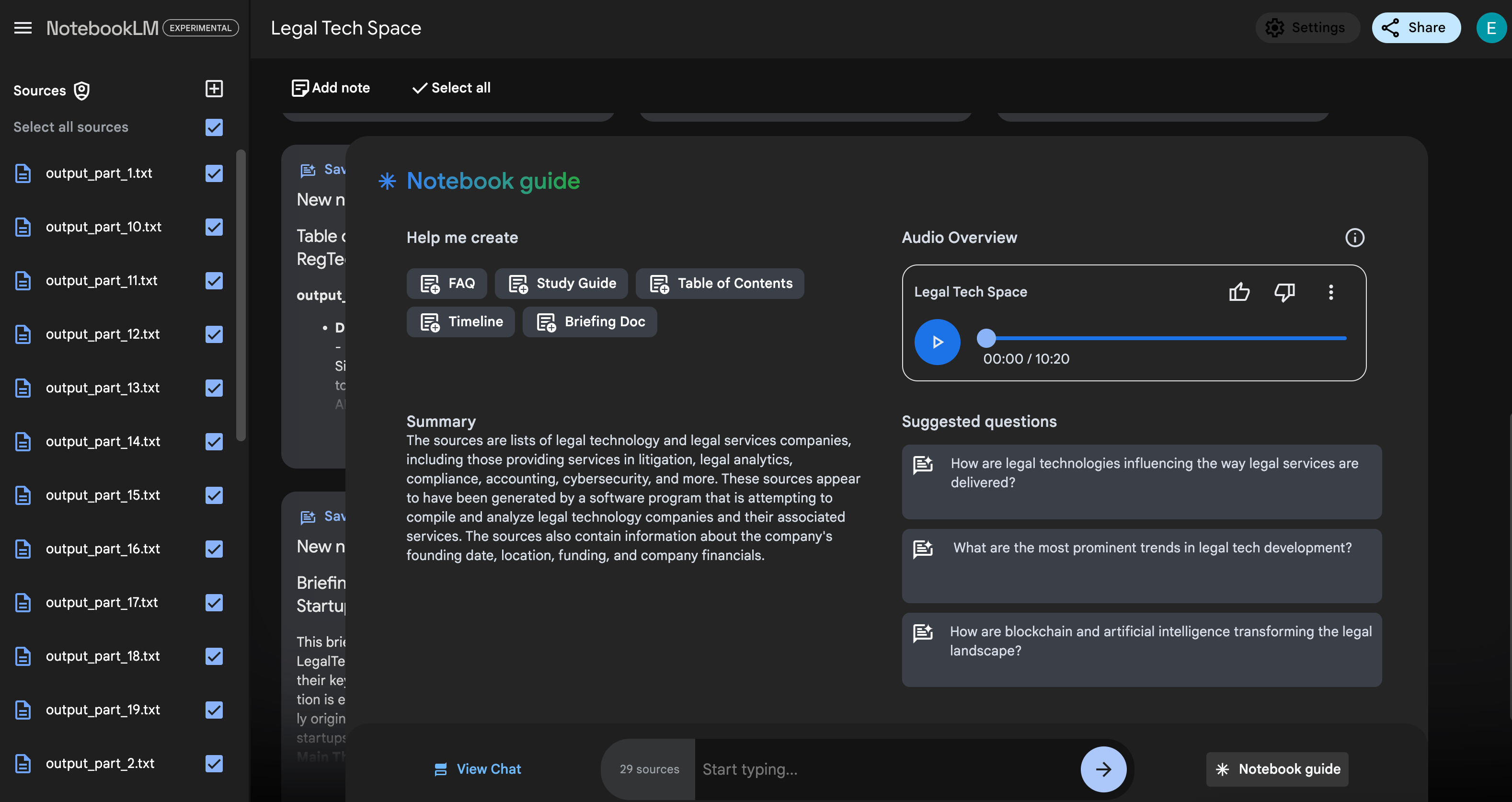
What do you think—good, bad, or ugly? Let me know! I might do more like this…